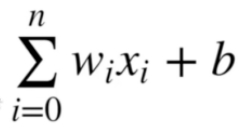Machine Learning
✏️ Apuntes y conceptos básicos del🤖Machine Learning 🔥🐉 - ¡Que debes saber!
Temario 📘
Entornos (Instalación de Anaconda, Jupyter Notebook Online)
Curso básico de Python (Números, cadenas, listas, diccionarios, tuplas, conjuntos, operaciones, función range, map, filter, bucles, for y while, y funciones lambda)
Módulo Numpy (Numpy con listas, funciones arange, ones, zeros, linspace, números aleatorios y arrays de 1 y 2 dimensiones)
Módulo Pandas (Series, Data Frames, selección de datos, modificación de filas, tratar valores nulos, agrupación por columnas, combinar Data Frames, Merge y Join en Data Frames, leer ficheros tipo excel, leer páginas web HTTML, grabar Data Frames, en tablas SQL y gráficos con pandas)
Módulo Matplotlib (gráficos, multigráficos, tamaño del gráfico, crear 2 gráficos en la misma figura, color del gráfico, tipo de línea y marcadores)
Scikit Learn es el paquete de machine learning más popular y tiene muchos algoritmos pre-construidos. Incluye varios algoritmos de clasificación, regresión y análisis de grupos entre los cuales están máquinas de vectores de soporte, bosques aleatorios, Gradient boosting, K-means y DBSCAN. Está diseñada para interoperar con las bibliotecas numéricas y científicas NumPy y SciPy. Se install
pip install scikit-learny en condaconda install -c anaconda scikit-learn.
¿Qué es el Marchine Learning?
Machine learning o aprendizaje de máquinas o aprendizaje automático, es el subcampo de las ciencias de la computación y una rama de la inteligencia artificial, cuyo objetivo es desarrollar técnicas que permitan que las computadoras aprendan.
Machine learning es un método de análisis de datos que automatiza la contrucción de un modelo analítico.
Machine learning permite a los ordenadores encontrar soluciones a problemas, sin ser explíitamente programados para ello, gracias al uso de algoritmos, que aprenden de los datos.
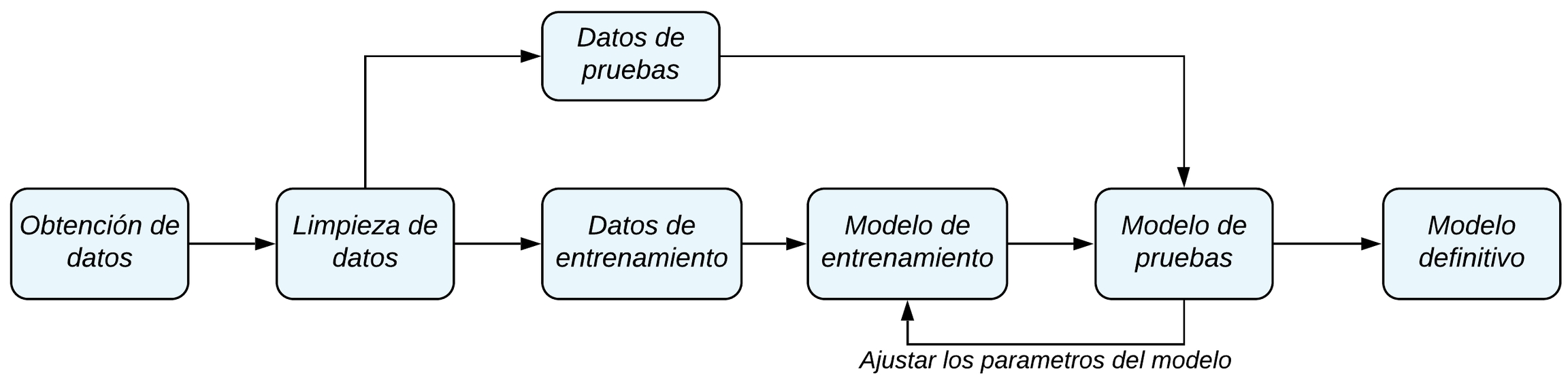
Procesos de Machine Learning
Tipos de algoritmos de Machine Learning
Aprendizaje supervizado: Este algoritmo necesita datos previamente etiquetados (solucinados) para aprender a realizar el trabajo. En base a estos datos, el algoritmo es capaz de aprender a resolver problemas futuros similares.
Aprendizaje no supervizado: Este algoritmo necesita indicaciones previas, que le enseñan a comprender y analizar la información, para resolver problemas futuros similares. No necesita datos previamente etiquetados.
Aprendizaje de refuerzo: Este algoritmo aprende por su cuenta, en base de unos conocimientos previamente introducidos y a la práctica que realiza sobre los problemas aprendiendo en función del éxito o fracaso que obtiene al resolver los problemas.
Algoritmos de Machine Learning 🐍📊
Regresión Lineal es una aproximación para modelar la relación entre una varible escalar dependiente "y" y una o más variables explicativas "x".
Regresión Logística es un tipo de análisis de regresión, utilizado para predecir el resultado de una variable categórica (una variable que puede adoptar un númerolimitado de categorías) en función de otras variables independientes.
k vecinos más próximos - KNN en el reconocimiento de patrones, este algoritmo es usado como método de clasificación de objetos, basado en un entrenamiento mediante ejemplos cercanos en el espacio de los elementos.
Arboles de Decisión dado un conjunto de datos, se fabrican diagramas de contrucciones lógicas, que sirven para representar y categorizar una serie de condiciones que ocurren de forma sucesiva, para la resolución de problema.
Bosques Aleatorios - Random Forest es una combinación de árboles de decisión, donde cada árbol selecciona una clase y luego se combinan las decisiones de cada árbol, para seleccionar una clase final ganadora.
Máquinas de Vectores de Soporte - Support Vector Machine - SVM representa los puntos de muestra en el espacio, separando las clases en dos espacios lo más amplio posible mediante un hiperplano de separación, denominado vector de soporte.
Algoritmo de K-Medias tiene como objetivo la partición de un conjunto de 'n' objetivos en 'k' grupos, en el cada observación pertenece al grupo cuyo valor medio es más cercano.
Deep Learning 🧠🌋
Redes Neuronales
Marco teórico, y representación analógica de las redes reuronales.
(Neurona y Perceptrón)
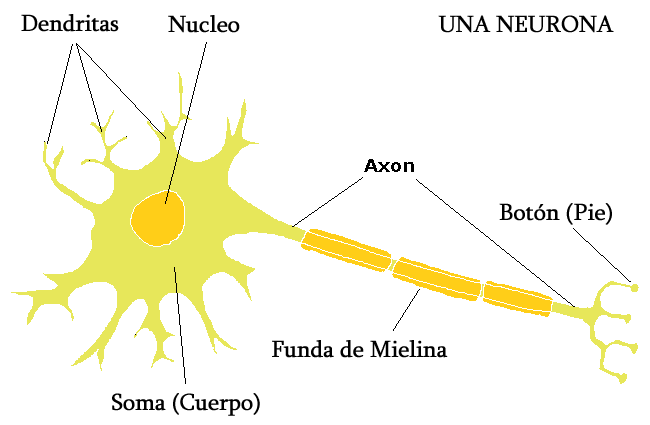
Una neurona es una célula y el componente principal del sistema nervioso, cuya función principal es recibir, precesar y transmitir información a través de señales químicas y eléctricas.
Se dividen en tres partes principales:
Soma: cuerpo celular o núcle.
Dentritas: Prolongaciones cortas que reciben información y la transmiten al Soma.
Axón: Prolongación corta que conduce los impulsos hacia otra neurona.
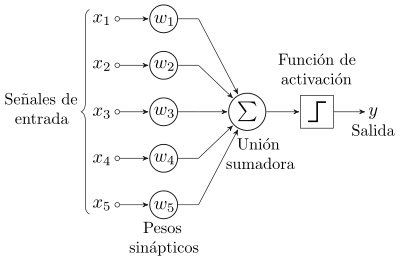
Perceptrón
Un perceptrón es una neurona artificial.
Se une con otros perceptrones para crear una red neuranol artifical.
Cada perceptrón tiene:
Canales de entrada (x1, x2, .. xn) (Dentritas)
Función de activación (Soma o núcle)
Canal de salida (y) (Axón)
Su representación matemática es:
Redes Neuronales Artificiales
Una red reuronal artificial consiste en un conjunto de reuronas artificiales (perceptrones) conectadas entre sí para transmitirse señales.
La información de entrada atraviesa la red neuronal (donde se somete a diversas operaciones).
Cada neurona aritificial está conectada con otras neuronas a través de unos enlaces. En estos enlaces, el valor de salida de la neurona es multiplicado por un valor (peso de enlace).
A la salida de la neurona, está la función de activación que modifica el valor del resultado de esa neurona, que posteriormente debe enviarse a la siguiente neurona.
Función de Activación
Funciones de activación de una neurona actificial sirve para definir el valor de salida en función de los datos de entrada.
La función de activación se encarga de devolver una salida a partir de un valor de entrada, normalmente el conjunto de valores de salida en un rango determinado como (0,1) o (-1,1). "Referencia bibliografica".
Existen diferentes tipos de funciones de activación:
Sigmoide: La función sigmoide transforma los valores introducidos a una escala (0,1), donde los valores altos tienen de manera asintótica a 1 y los valores muy bajos tienden de manera asintótica a 0.
Tanh - Tangente hiperbólica: La función tangente hiperbólica transforma los valores introducidos a una escala (-1,1), donde los valores altos tienen de manera asintótica a 1 y los valores muy bajos tienden de manera asintótica a -1.
ReLU - Unidad lineal rectificada: La función ReLU transforma los valores introducidos anulando los valores negativos y dejando los positivos tal y como entran.
Leaky ReLU - Unidad lineal rectificada: La función Leaky ReLU transforma los valores introducidos multiplicando los negativos por un coeficiente rectificativo y dejando los positivos según entran.
Softmax – Unidad lineal rectificada: La función Softmax transforma las salidas a una representación en forma de probabilidades, de tal manera que el sumatorio de todas las probabilidades de las salidas de 1.
Función de Coste
Para evaluar el rendimiento de una reurona, utilizaremos las funciones de coste.
Las funciones de coste sirven para medir qué distancia hay entre el valor estimado por la neurona y el valor real.
Significado de las varibles utilizadas en las funciones de coste
y: Representa el valor real
a: Representa el valor estimado por la reunona
w: Peso del enlace de una neurona a otra
x: Valor de la entrada en la neurona
b: Valor residual o bias
z: Valor que pasamos a las función de activación para calcular el valor estimado "a"
Ecuación de la función de coste: z = ( w * x ) + b
Tipos de funciones de coste:
Función de coste cuadrático:
Los errores se hace más grande, debido a que están al cuadrado
Esta función puede ralentizar la velocidad de aprendizaje de nuestra red neuronal artificial
Esta es la ecuación matemática para calcularla: C = ∑ ( y - a )² ∕ n
Función de entropía cruzada
Cuánto mayor es la diferencia entre el valor real y la predicción de la neurona, mayor será la rapidez de aprendizaje.
Permite una mayor rapidez en el aprendizaje de nuestra red neuronal artificial
Esta es la fórmula matemática para calcularla: C = ( -1 / n ) ∑ ( y ㏑( a ) + ( 1 - y ) * ㏑( 1 - a ) )
Algoritmo del gradiente descendiente
El algoritmo del gradiente descendiente es un algoritmo de optimización para encontrar el valor mínimo de una función de coste, es decir, encontrar el valor de los pesos exactos "W" en nuestra red neuronal para que el valor de la función de coste "C" sea el valor mínimo posible.
TensorFlow 🔥 -> Ir al READMED.md 🚀
La Página de PlayGround de TensorFlow, es un ejemplo de como funciona estos algoritmos y las redes neuronales.
Última actualización